限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
集群限流保证下游服务,单机限流,保护自己的服务不在极端情况被打呲。常用的限流算法是令牌桶和漏桶,另外有时候我们还使用计数器来进行限流,主要用来限制总并发数,比如数据库连接池、线程池、秒杀的并发数。
计数器
计数器是最简单的一种限流算法,比如我们规定1分钟内请求数量不超过100个。那么可以在一开始的时候设置一个计数器,每个请求过来时计数器+1,如果计数器的值大于100,并且与第一个请求时间间隔在1分钟内,就限流。如果时间间隔大于1分钟,且计数器的值还在限流范围内,就重置计数器。
这个算法有临界值问题。比如一个用户在一分钟的59秒发送了了100个请求,然后又在第二分钟的第一秒发送了100个请求,由于计数器重置,这2秒内处理了200个请求。实际是超出了限流的阈值的,容易在瞬间压垮我们的应用。此外这种限流方式不平滑,在大流量情况下,在一分钟开始的第一秒就打满了100个请求,后续请求都会被拒绝掉,然后第二分钟又进来100个请求,就会呈现阶梯状流量。
出现这种问题的原因是精度不够引起的,可以通过滑动窗口算法解决这个问题。
滑动窗口
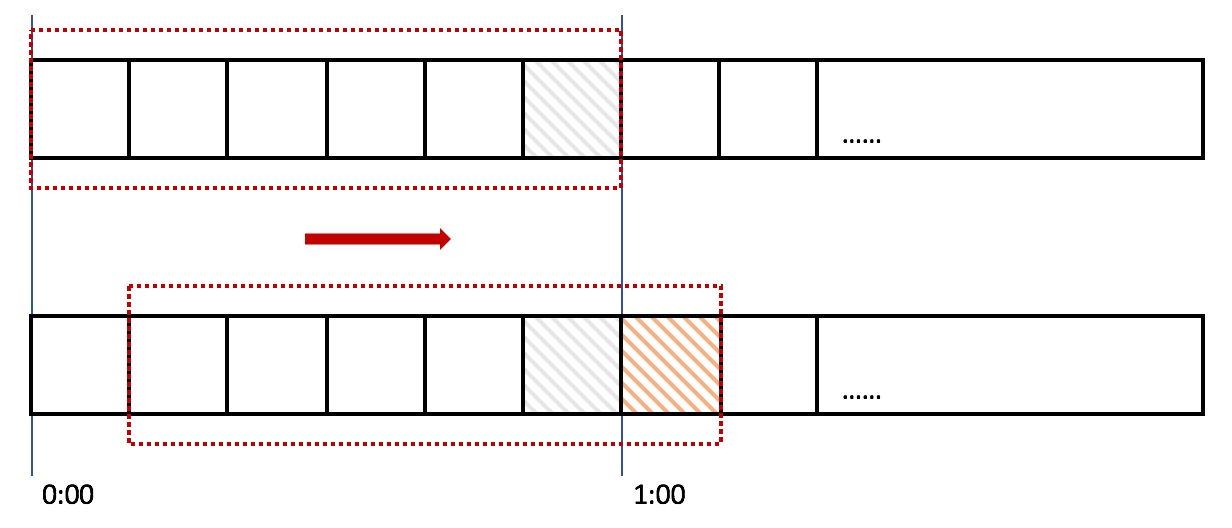
在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器,比如当一个请求在0:35秒的时候到达,那么0:30~0:39对应的计数器就会加1。
那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,0:59到达的100个请求会落在灰色的格子中,而1:00到达的请求会落在橘黄色的格子中。当时间到达1:00时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触发了限流。
再来回顾一下刚才的计数器算法,可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
计数器 VS 滑动窗口
计数器算法是最简单的算法,可以看成是滑动窗口的低精度实现。滑动窗口由于需要存储多份的计数器(每一个格子存一份),所以滑动窗口在实现上需要更多的存储空间。也就是说,如果滑动窗口的精度越高,需要的存储空间就越大。
令牌桶(Token Bucket)
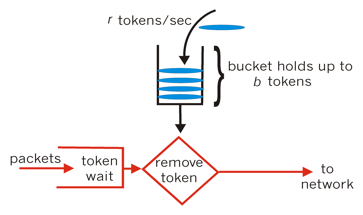
令牌桶算法是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。令牌桶算法的描述如下:
- 假设用户配置平均发送速率为r,则每隔1/r秒一个令牌被加入桶中;
- 桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝;
- 当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上;
- 如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
漏桶(Leaky Bucket)
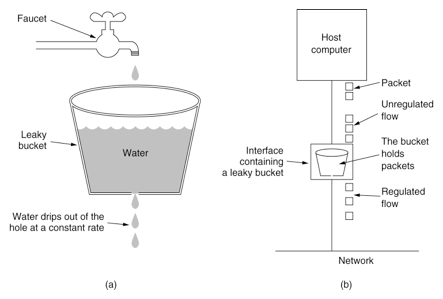
漏桶有两种实现,一种是 as a meter,另一种是 as a queue。
As a meter
第一种实现是和令牌桶等价的,只是表述角度不同。
漏桶作为计量工具(The Leaky Bucket Algorithm as a Meter)时,可以用于流量整形(Traffic Shaping)和流量控制(TrafficPolicing),漏桶算法的描述如下:
- 一个固定容量的漏桶,按照常量固定速率流出水滴;
- 如果桶是空的,则不需流出水滴;
- 可以以任意速率流入水滴到漏桶;
- 如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
As a queue
第二种实现是用一个队列实现,当请求到来时如果队列没满则加入到队列中,否则拒绝掉新的请求。同时会以恒定的速率从队列中取出请求执行。
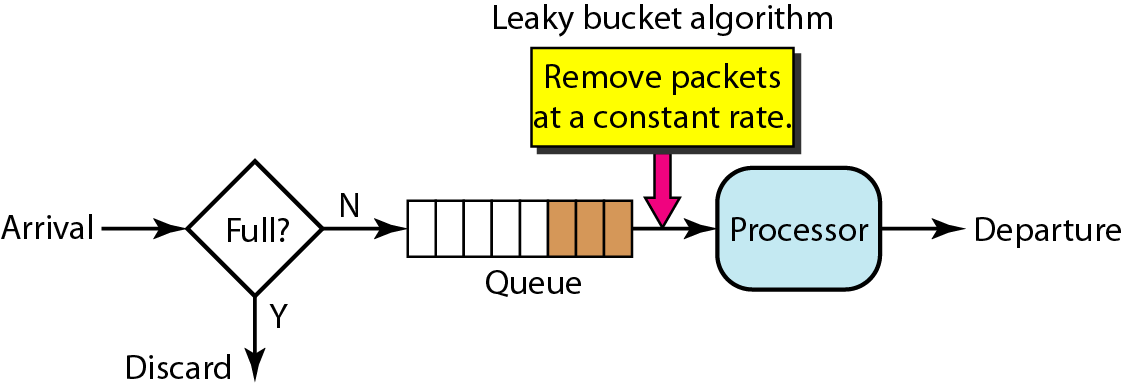
对于该种算法,固定的限定了请求的速度,不允许流量突发的情况。
比如初始时桶是空的,这时1ms内来了100个请求,那只有前10个会被接受,其他的会被拒绝掉。
不过,当桶的大小等于每个ticket流出的水大小时,第二种漏桶算法和第一种漏桶算法是等价的。也就是说,as a queue是as a meter的一种特殊实现。
令牌桶 VS 漏桶
- 令牌桶是按照固定速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数减为零时则拒绝新的请求;
- 漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入的请求数累积到漏桶容量时,则新流入的请求被拒绝;
- 令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌),并允许一定程度突发流量;
- 漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次又是2),从而平滑突发流入速率;
- 令牌桶允许一定程度的突发,而漏桶主要目的是平滑流入速率;
- 两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
Guava的RateLimiter进行限流
Google开源工具包Guava提供了限流工具类RateLimiter,该类基于令牌桶算法实现流量限制,使用十分方便。
RateLimiter有两种限流模式,一种为稳定模式(SmoothBursty 令牌生成速度恒定),一种为渐进模式(SmoothWarmingUp:令牌生成速度缓慢提升直到维持在一个稳定值)。
这里有段注释:
/**
* Last, but not least: consider a RateLimiter with rate of 1 permit per second, currently
* completely unused, and an expensive acquire(100) request comes. It would be nonsensical
* to just wait for 100 seconds, and /then/ start the actual task. Why wait without doing
* anything? A much better approach is to /allow/ the request right away (as if it was an
* acquire(1) request instead), and postpone /subsequent/ requests as needed. In this version,
* we allow starting the task immediately, and postpone by 100 seconds future requests,
* thus we allow for work to get done in the meantime instead of waiting idly.
**/
以上,表明这个版本的RateLimiter会预消费后续的流量额度。比如调用acquire(100),而限制的qps是10,在未被限流情况下,RateLimiter会通过这个acquire(100),而不是被阻塞。之后的10秒内的acquire()才会被阻塞住。
SmoothBursty中几个属性的含义
/**
* The currently stored permits.
* 当前存储令牌数
*/
double storedPermits;
/**
* The maximum number of stored permits.
* 最大存储令牌数
*/
double maxPermits;
/**
* The interval between two unit requests, at our stable rate. E.g., a stable rate of 5 permits
* per second has a stable interval of 200ms.
* 添加令牌时间间隔
*/
double stableIntervalMicros;
/**
* The time when the next request (no matter its size) will be granted. After granting a request,
* this is pushed further in the future. Large requests push this further than small requests.
* 下一次请求可以获取令牌的起始时间
* 由于RateLimiter允许预消费,上次请求预消费令牌后
* 下次请求需要等待相应的时间到nextFreeTicketMicros时刻才可以获取令牌
*/
private long nextFreeTicketMicros = 0L; // could be either in the past or future
根据令牌桶算法,桶中的令牌是持续生成存放的,有请求时需要先从桶中拿到令牌才能开始执行,谁来持续生成令牌存放呢?
-
一种解法是,开启一个定时任务,由定时任务持续生成令牌。这样的问题在于会极大的消耗系统资源,如某接口需要分别对每个用户做访问频率限制,假设系统中存在6W用户,则至多需要开启6W个定时任务来维持每个桶中的令牌数,这样的开销是巨大的。
-
另一种是触发式添加令牌。在取令牌的时候,通过计算上一次添加令牌和当前的时间差,计算出这段时间应该添加的令牌数,然后往桶里添加,添加完令牌之后再执行取令牌逻辑。
- curr_mill_second = 当前毫秒数
- last_mill_second = 上一次添加令牌的毫秒数
- r = 添加令牌的速率
- reserve_permits = (curr_mill_second-last_mill_second)/1000 * r
SmoothBursty采用的是触发式添加令牌的方式,实现方法为resync(long nowMicros)
/**
* Updates {@code storedPermits} and {@code nextFreeTicketMicros} based on the current time.
*/
void resync(long nowMicros) {
// if nextFreeTicket is in the past, resync to now
if (nowMicros > nextFreeTicketMicros) {
double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros();
storedPermits = min(maxPermits, storedPermits + newPermits);
nextFreeTicketMicros = nowMicros;
}
}
该函数会在每次获取令牌之前调用,其实现思路为,若当前时间晚于nextFreeTicketMicros,则计算该段时间内可以生成多少令牌,将生成的令牌加入令牌桶中并更新数据。这样一来,只需要在获取令牌时计算一次即可。
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
resync(nowMicros);
long returnValue = nextFreeTicketMicros; // 返回的是上次计算的nextFreeTicketMicros
double storedPermitsToSpend = min(requiredPermits, this.storedPermits); // 可以消费的令牌数
double freshPermits = requiredPermits - storedPermitsToSpend; // 还需要的令牌数
long waitMicros =
storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros); // 根据freshPermits计算需要等待的时间
this.nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros); // 本次计算的nextFreeTicketMicros不返回
this.storedPermits -= storedPermitsToSpend;
return returnValue;
}
该函数用于获取requiredPermits个令牌,并返回需要等待到的时间点。其中,storedPermitsToSpend为桶中可以消费的令牌数,freshPermits为还需要的(需要补充的)令牌数,根据该值计算需要等待的时间,追加并更新到nextFreeTicketMicros。
需要注意的是,该函数的返回是更新前的(上次请求计算的)nextFreeTicketMicros,而不是本次更新的nextFreeTicketMicros,也就是说,本次请求需要为上次请求的预消费行为埋单,这也是RateLimiter可以预消费(处理突发)的原理所在。若需要禁止预消费,则修改此处返回更新后的nextFreeTicketMicros值。
分布式限流
redis 4.0中提供了redis-cell模块(需安装),基于令牌桶算法实现。
官方wiki:https://github.com/brandur/redis-cell
命令:CL.THROTTLE
CL.THROTTLE user123 15 30 60 3
- user123: redis key
- 15:官方叫max_burst,其值为令牌桶的容量 - 1, 首次执行时令牌桶会默认填满
- 30:与下一个参数一起,表示在指定时间窗口内允许访问的次数
- 60:指定的时间窗口,单位:秒
- 3: 表示本次要申请的令牌数,不写则默认为 1
以上命令表示从一个初始值为15的令牌桶中取3个令牌,该令牌桶的速率限制为30次/60秒。
127.0.0.1:6379> CL.THROTTLE user123 15 30 60
1) (integer) 0
2) (integer) 16
3) (integer) 15
4) (integer) -1
5) (integer) 2
返回值含义:
- 是否成功,0:成功,1:拒绝
- 令牌桶的容量,大小为初始值+1
- 当前令牌桶中可用的令牌
- 若请求被拒绝,这个值表示多久后才令牌桶中会重新添加令牌,单位:秒,可以作为重试时间
- 表示多久后令牌桶中的令牌会存满